处理
能谱信息
| 元素系 | 代表通道 | 代表核素 | 特征能量 (keV) | 土壤意义 |
|---|---|---|---|---|
| K 系 | ~1460 keV | K-40 | 1460 | 钾元素含量 |
| Th 系 | ~2615 keV | Tl-208(来自 Th-232 系) | 2615 | 钍元素含量 |
| U 系 | ~609 keV | Bi-214(来自 U-238 系) | 609 | 铀元素含量 |
目前的能谱探测有两种元件:NaI和CsI,其中:
- 通道总数:1024
- 200通道:608keV Bi-214 (U-238系)
- 490通道:1460keV K-40 (自然放射性)
- 868通道:2614keV Tl-208 (Th-232系)
数据处理方法
SNIP背景剔除
class SNIP:
def __init__(self, iterations=40):
self.iterations = iterations
self.background_ = None
self.net_counts_ = None
def fit(self, counts):
"""
对输入谱执行 SNIP 背景估计(对数域版本)
"""
counts = np.array(counts, dtype=float)
# 为防止 log(0),加上一个很小的常数
y = np.log(counts + 1)
bg = y.copy()
for m in range(1, self.iterations + 1):
temp = bg.copy()
for i in range(m, len(y) - m):
bg[i] = min(bg[i], (temp[i - m] + temp[i + m]) / 2.0)
# 转回线性域
bg = np.exp(bg) - 1
self.background_ = bg
self.net_counts_ = counts - bg
return self.background_
def transform(self, counts):
if self.background_ is None:
self.fit(counts)
return self.net_counts_
def fit_transform(self, counts):
self.fit(counts)
return self.net_counts_
def process_csv(self, input_csv, output_csv, counts_column='counts'):
"""
批量处理 CSV 文件
:param input_csv: 原始 CSV 文件路径
:param output_csv: 输出 CSV 文件路径
:param counts_column: 包含通道计数的列名
"""
df = pd.read_csv(input_csv)
bg_list = []
net_list = []
net_total_counts = [] # 添加用于存储净计数总和的列表
for idx, row in df.iterrows():
# 将字符串列表解析为 Python list
counts = ast.literal_eval(row[counts_column])
bg = self.fit(counts)
net = self.transform(counts)
bg_list.append([round(float(i), 3) for i in bg])
net_list.append([round(float(i), 3) for i in net])
net_total_counts.append(round(float(np.sum(net)), 3))
# 新增列
df['background'] = bg_list
df['net_counts'] = net_list
df['net_total_counts'] = net_total_counts # 添加净计数总和列
# 创建新的DataFrame,只保留需要的字段
new_df = df[['farm_id', 'collection_time', 'latitude', 'longitude','counts', 'background', 'net_counts', 'net_total_counts']]
# 保存
new_df.to_csv(output_csv, index=False)
print(f'处理完成,已保存到 {output_csv}')
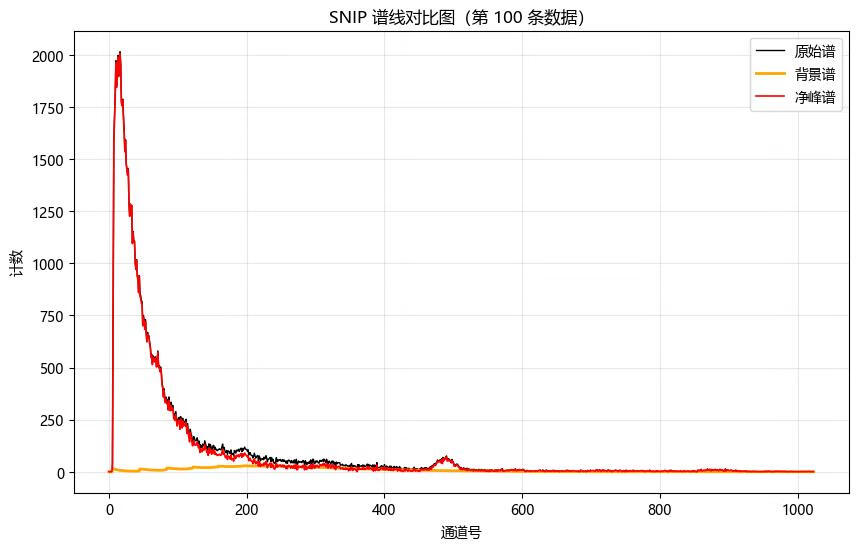
def plot_spectrum(self, input_csv, index=0, counts_col='counts', bg_col='background', net_col='net_counts'):
"""
绘制指定索引的谱线对比图(原始谱、背景、净峰谱)
:param input_csv: CSV 文件路径(包含 counts、background、net_counts)
:param index: 要绘制的行号(从 0 开始)
:param counts_col: 原始谱列名
:param bg_col: 背景谱列名
:param net_col: 净谱列名
"""
# 读取数据
df = pd.read_csv(input_csv)
# 检查索引是否超出范围
if index < 0 or index >= len(df):
raise IndexError(f"索引 {index} 超出范围(共有 {len(df)} 条数据)")
# 解析为 Python 列表
counts = np.array(ast.literal_eval(df.loc[index, counts_col]), dtype=float)
background = np.array(ast.literal_eval(df.loc[index, bg_col]), dtype=float)
net = np.array(ast.literal_eval(df.loc[index, net_col]), dtype=float)
# 绘图
plt.figure(figsize=(10, 6))
plt.plot(counts, label='原始谱', color='black', linewidth=1)
plt.plot(background, label='背景谱', color='orange', linewidth=2)
plt.plot(net, label='净峰谱', color='red', linewidth=1.2)
plt.xlabel('通道号')
plt.ylabel('计数')
plt.title(f'SNIP 谱线对比图(第 {index+1} 条数据)')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
调用方法(默认迭代40次):
# SNIP初始化
snip = SNIP(iterations=40)
snip.process_csv('../file/point_area_a.csv', '../file/snip_processed_area_a.csv', counts_column='counts')
snip.process_csv('../file/point_area_b.csv', '../file/snip_processed_area_b.csv', counts_column='counts')
snip.plot_spectrum('../file/snip_processed_area_a.csv', index=99) # 绘制第100条数据
窗口求和
class SpectrumPeak:
"""
根据指定通道和窗口范围计算能谱峰强度(窗口求和),支持批量多通道处理
"""
def __init__(self, counts_column='counts'):
self.counts_column = counts_column # CSV 中的计数列名
def compute_peak(self, counts, channel, window):
"""
计算指定通道附近窗口的计数和
:param counts: 样本的计数列表
:param channel: 中心通道
:param window: 窗口范围(正负范围)
:return: 窗口内计数和
"""
start = max(0, channel - window)
end = min(len(counts), channel + window + 1) # python 切片是左闭右开
return sum(counts[start:end])
def process_csv(self, input_csv, output_csv, peaks):
"""
处理 CSV 文件,计算峰强度,并保存新 CSV
:param input_csv: 输入 CSV 路径
:param output_csv: 输出 CSV 路径
:param peaks: dict, {列名: (中心通道, 窗口范围)}
例如: {'K40_peak': (490, 5), 'U238_peak': (600, 7)}
"""
df = pd.read_csv(input_csv)
# 先把原 counts 列解析成列表,方便重复使用
counts_list = df[self.counts_column].apply(ast.literal_eval)
for peak_name, (channel, window) in peaks.items():
df[peak_name] = counts_list.apply(lambda x: self.compute_peak(x, channel, window))
df.to_csv(output_csv, index=False)
print(f'处理完成,已保存到 {output_csv}')
调用方法:
# 获取指定通道的窗口求和
sp = SpectrumPeak(counts_column='net_counts')
# 定义要计算的峰,键是输出列名,值是 (中心通道, 窗口)
peaks_to_calc = {
'Bi214_peak': (200, 10),
'K40_peak': (490, 10),
'Tl208_peak': (868, 10)
}
sp.process_csv(
input_csv='../file/snip_processed_area_a.csv',
output_csv='../file/data_peaks_area_a.csv',
peaks=peaks_to_calc
)
主成分分析
class SpectrumPCA:
"""
光谱主成分分析(PCA)封装类
支持 CSV 文件批量处理、自动保存主成分结果
"""
def __init__(self, n_components=3):
"""
初始化 PCA 模型
:param n_components: 主成分数量(默认 3)
"""
self.n_components = n_components
self.pca_model = PCA(n_components=n_components)
self.components_ = None
self.explained_variance_ratio_ = None
self.pca_scores_ = None
def _parse_counts(self, counts_str):
"""
将字符串 "[1, 2, 3]" 转换为 numpy 数组
"""
if isinstance(counts_str, str):
return np.array(ast.literal_eval(counts_str), dtype=float)
elif isinstance(counts_str, (list, np.ndarray)):
return np.array(counts_str, dtype=float)
else:
raise ValueError("counts 列格式错误,应为字符串或列表")
def fit_transform_csv(self, input_csv, output_csv=None, counts_column='counts'):
"""
从 CSV 文件读取能谱数据,执行 PCA 并保存结果
:param input_csv: 输入 CSV 文件路径
:param output_csv: 输出 CSV 文件路径(可选)
:param counts_column: 光谱列名(默认 'counts')
:return: 包含 PCA 结果的 DataFrame
"""
# === 1. 读取 CSV ===
df = pd.read_csv(input_csv)
print(f"✅ 成功读取 {len(df)} 条样本")
# === 2. 转换 counts 列为矩阵 ===
spectra = np.array([self._parse_counts(c) for c in df[counts_column]])
print(f"每条光谱通道数: {spectra.shape[1]}")
# === 3. 执行 PCA ===
self.pca_scores_ = self.pca_model.fit_transform(spectra)
self.components_ = self.pca_model.components_
self.explained_variance_ratio_ = self.pca_model.explained_variance_ratio_
# === 4. 将主成分结果添加到 df ===
for i in range(self.n_components):
df[f'PC{i+1}'] = self.pca_scores_[:, i]
# === 5. 可选保存结果 ===
if output_csv:
base, ext = os.path.splitext(output_csv)
result_csv = f"{base}_pca.csv"
variance_csv = f"{base}_variance.csv"
# 保存主成分结果
df.to_csv(result_csv, index=False)
# 保存方差贡献率信息
var_df = pd.DataFrame({
'PC': [f'PC{i+1}' for i in range(self.n_components)],
'Explained_Variance_Ratio': self.explained_variance_ratio_
})
var_df.to_csv(variance_csv, index=False)
print(f"📂 PCA结果已保存至: {result_csv}")
print(f"📊 方差贡献率已保存至: {variance_csv}")
return df
# ==================== 方差贡献率柱状图 ====================
def plot_variance_ratio(self):
if self.explained_variance_ratio_ is None:
raise ValueError("请先运行 fit_transform_csv()")
plt.figure(figsize=(6, 4))
plt.bar(range(1, len(self.explained_variance_ratio_) + 1),
self.explained_variance_ratio_ * 100, color='skyblue')
plt.xlabel("主成分")
plt.ylabel("方差贡献率 (%)")
plt.title("PCA 方差贡献率")
plt.grid(True, alpha=0.3)
plt.show()
# ==================== PCA 散点图 ====================
def plot_scatter(self, df, pc_x=1, pc_y=2):
pc_x_col = f'PC{pc_x}'
pc_y_col = f'PC{pc_y}'
if pc_x_col not in df.columns or pc_y_col not in df.columns:
raise ValueError("DataFrame 中缺少指定的 PCA 列,请先运行 fit_transform_csv()")
plt.figure(figsize=(6, 6))
plt.scatter(df[pc_x_col], df[pc_y_col], alpha=0.7, edgecolor='k')
plt.xlabel(pc_x_col)
plt.ylabel(pc_y_col)
plt.title(f'PCA 散点图 ({pc_x_col} vs {pc_y_col})')
plt.grid(True, alpha=0.3)
plt.show()
# ==================== 空间可视化 ====================
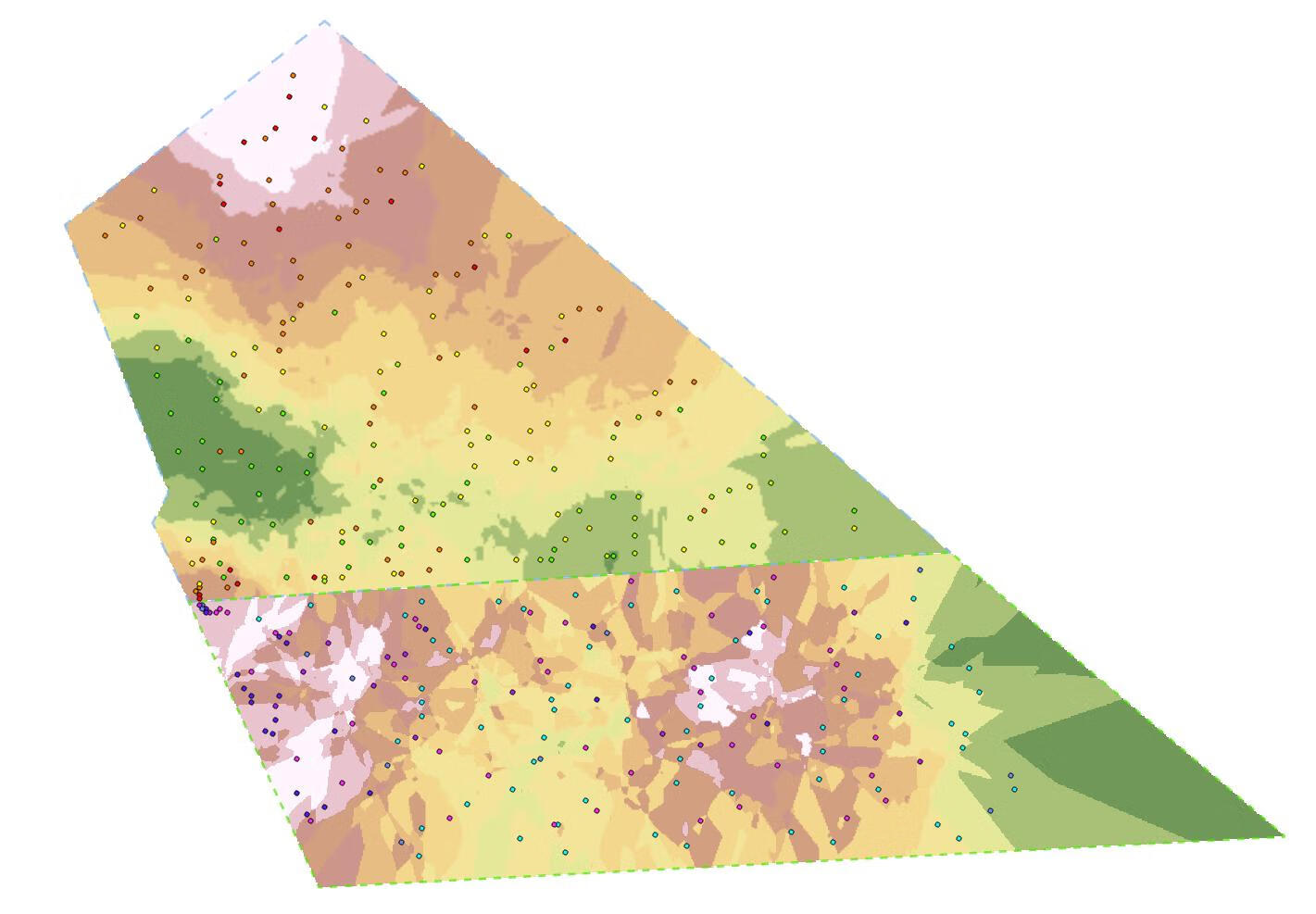
def plot_spatial_pca(self, df, pc=1, lat_col='latitude', lon_col='longitude',
method='scatter', grid_res=100):
"""
绘制 PCA 空间分布图
:param df: 包含经纬度和 PCA 列的 DataFrame
:param pc: PCA 编号(1,2,3,...)
:param lat_col: 纬度列名
:param lon_col: 经度列名
:param method: 'scatter' 或 'heatmap'
:param grid_res: 热力图插值网格分辨率
"""
pc_col = f'PC{pc}'
if pc_col not in df.columns:
raise ValueError(f"{pc_col} 列不存在,请先运行 PCA")
lats = df[lat_col].values
lons = df[lon_col].values
values = df[pc_col].values
if method == 'scatter':
plt.figure(figsize=(8, 6))
sc = plt.scatter(lons, lats, c=values, cmap='viridis', s=50, edgecolor='k')
plt.colorbar(sc, label=f'{pc_col} 值')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title(f'{pc_col} 空间散点图')
plt.grid(True, alpha=0.3)
plt.show()
elif method == 'heatmap':
# 创建网格
lon_grid = np.linspace(lons.min(), lons.max(), grid_res)
lat_grid = np.linspace(lats.min(), lats.max(), grid_res)
lon_mesh, lat_mesh = np.meshgrid(lon_grid, lat_grid)
# 插值
grid_values = griddata((lons, lats), values, (lon_mesh, lat_mesh), method='cubic')
# 绘制热力图
plt.figure(figsize=(8, 6))
hm = plt.imshow(grid_values, origin='lower',
extent=(lons.min(), lons.max(), lats.min(), lats.max()),
cmap='viridis', aspect='auto')
plt.colorbar(hm, label=f'{pc_col} 值')
plt.scatter(lons, lats, c='white', s=10, alpha=0.8) # 原始点位置
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title(f'{pc_col} 空间热力图')
plt.show()
else:
raise ValueError("method 参数只支持 'scatter' 或 'heatmap'")
调用方法:
# PCA初始化
pca = SpectrumPCA(n_components=3)
# 对 CSV 数据进行 PCA 并保存结果
df_area_a = pca.fit_transform_csv(input_csv="../file/snip_processed_area_a.csv", output_csv="../file/area_a.csv", counts_column='net_counts')
df_area_b = pca.fit_transform_csv(input_csv="../file/snip_processed_area_b.csv", output_csv="../file/area_b.csv", counts_column='net_counts')
# # 绘制方差贡献率图
# pca.plot_variance_ratio()
# # 绘制主成分散点图(PC1 vs PC2)
# pca.plot_scatter(df_area_a, pc_x=1, pc_y=2)
# # 绘制空间散点图(PC1)
# pca.plot_spatial_pca(df_area_a, pc=1, method='scatter')
# # 绘制空间热力图(PC1)
# pca.plot_spatial_pca(df_area_a, pc=1, method='heatmap', grid_res=200)